1. Introduction
Le travail que nous présentons est le résultat d'une année de recherches
dans le domaine de
l'informatisation des dictionnaires anciens, plus particulièrement du Dictionnaire
Universel de
Furetière revu par Basnage de Bauval 1702 (désormais DU2),
recherches qui ont été menées
essentiellement grâce à une subvention allouée par la
Délégation à la Langue Française.
Une version développée de cette présentation est à
paraître chez Champion. En conséquence,
nous ne détaillerons pas les raisons qui nous ont amenées à choisir le
Basnage 1702 (désormais
DU2) et le Trévoux 1704. On peut simplement rappeler, avant
d'entrer dans le vif de
l'informatisation, que ces deux dictionnaires, de type encyclopédique, ont fait l'histoire
lexicographique du XVIIIe siècle, et ont aidé l'Encyclopédie
Diderot-D'Alembert à naître.
Nous consacrons la suite de notre article à la présentation rapide du mode de
balisage (2), puis
à l'analyse et au balisage de l'article, en particulier du champ grammatical (3).
2. Principes adoptés pour le balisage du DU2
Le mode d'informatisation choisi dans notre projet est le balisage, technique qui consiste
à
isoler les parties logiques d'un document (par exemple, l'entrée, la partie grammaticale, la
définition, etc.) à l'aide de jalons (appelés balises) sans modifier le contenu
ou
l'ordonnancement des parties textuelles.
Dans cette section, nous présentons brièvement les principes qui ont
présidé à la première
phase d'informatisation du DU2. Dans la première phase d'analyse que nous
voulons effectuer
(350 articles), notre entreprise est assez ambitieuse puisque nous souhaitons réaliser autant
que
possible un balisage fin et détaillé. Une évaluation à l'issue de ce
premier travail nous permettra
d'estimer dans quelle mesure un tel traitement apparaît raisonnablement applicable à
l'ensemble
de l'ouvrage.
2.1. Priviliégier l'utilisation de normes et de standards reconnus
L'informatisation du DU2 est une entreprise lourde et coûteuse. La saisie
des données est une
opération fastidieuse qui ne peut être automatisée, puisque la reconnaissance
optique de caractères
est exclue, le mauvais état des originaux et la présence des ligatures rendant
difficile la
reconnaissance des caractères individuels. La vérification des graphies ne peut pas
non plus être
automatisée, puisque l'orthographe n'est pas normalisée dans les textes qui nous
intéressent. Les
extraits du DU2 ont été saisis par deux étudiantes
vacataires [1] de l'Université de Lille 3 et de
nombreuses vérifications ont dû être effectuées. Par ailleurs, le balisage
des articles est un
traitement intellectuel requérant une expertise à la fois sur le plan informatique et
sur le plan
métalexicographique. Il semblait essentiel que le texte soit diffusé sur Internet et
qu'il soit encodé
à l'aide de normes et de standards [2] en usage dans la
communauté universitaire. Dans cette
perspective, nous avons préféré le langage de balisage SGML (Standard
Generalized Markup
Language) à des balisages « propriétaires »,
c'est-à-dire propres au système choisi, langage qui
nous a aussi paru plus intéressant sur le plan formel du fait de la rigueur qu'il impose.
Par ailleurs, nous avons essayé d'adapter les recommandations de balisage
proposées par la
« Text Encoding Initiative » (Sperberg-McQueen & Burnard 1994), initiative soutenue
par de nombreuses associations [3] qui essaient de promouvoir
des formats communs d'encodage
afin de faciliter l'échange et l'exploitation des corpus électroniques. Ces
recommandations se
traduisent par un ensemble de DTD SGML permettant de traiter différents types de textes
(prose,
textes versifiés, pièces de théâtre, corpus oraux, etc.). Nous nous
sommes bien entendu intéressées
aux recommandations proposées pour les dictionnaires « papier »
(Ide & Véronis 1995) et
nous les avons adaptées à notre objectif. Il va sans dire que de nombreux
éléments spécifiques ont
dû être ajoutés pour rendre compte de la structure des dictionnaires ancien.
2.2. Proposer une grille d'analyse systématique : la DTD
Notre entreprise d'informatisation s'appuie sur une grille d'analyse systématique pour
un sous-ensemble des champs. Nous faisons l'hypothèse d'une microstructure
régulière pour l'article type,
analyse qui s'appuie essentiellement sur des éléments formels : la
typographie, la distribution des
éléments et les indicateurs métalinguistiques. Cette analyse peut se traduire
techniquement par
l'élaboration d'une DTD (Description du Type de Document) en SGML,
une « grammaire type »
de l'article utilisant non seulement des éléments (des balises caractérisant
des parties textuelles),
mais aussi des attributs [4] permettant de systématiser le
codage et faciliter les requêtes. L'analyse
effectuée devrait permettre de proposer un texte informatisé qui répondra
à la fois aux besoins du
métalexicographe et à ceux de l'historien de la langue.
L'informatisation que nous proposons n'altère pas le texte d'origine, hormis quelques
modifications que nous considérons comme mineures. Ainsi, pour le texte balisé,
nous n'avons pas
conservé la mise en page en colonnes et les césures. Il serait sans doute souhaitable
de renvoyer
l'utilisateur à une image du texte original à partir du texte balisé [5], mais cette solution sera peut-être lourde à mettre en
œuvre. Le texte original étant conservé, il sera donc toujours possible
à
l'utilisateur d'interroger les formes textuelles sans exploiter les balises. Le balisage doit être
compris comme une proposition d'analyse du texte, mais d'autres accès au texte original
resteront
toujours possibles.
En tant que clé d'accès au texte, la typographie est bien entendu essentielle.
Elle sera
donc systématiquement codifiée, puisqu'elle ne peut pas être associée
de façon
systématique, comme dans certains dictionnaires récents, aux champs
informationnels.
Proposer une « grammaire type » des articles du DU2
peut passer pour une gageure.
Au regard des dictionnaires contemporains, ces ouvrages peuvent paraître fort peu
structurés, mais une fréquentation régulière du texte nous a fait
entrevoir dans de
nombreux champs une certaine régularité. Bien entendu, des styles ne peuvent
être
associés de manière systématique aux champs informationnels, mais la
typographie
demeure dans de nombreux cas (entrée principale, sous-entrée, par exemple) un
indice
fiable. La distribution de certains champs peut apparaître irrégulière, mais
des champs
comme l'entrée, le renvoi ou la partie grammaticale semblent avoir des positions stables
dans l'article. Les indicateurs métalinguistiques, s'ils ne présentent pas la
systématicité qui
caractérise les dictionnaires contemporains, se présentent sous des formes
relativement
codifiées. Ces considérations nous conduisent à penser qu'il est possible
de constituer une
grammaire type des articles du DU2, grammaire qui devra cependant présenter
une très
grande souplesse.
En outre, nous pensons qu'élaborer une telle grammaire est non seulement possible,
mais
souhaitable. Le recours à une structure de ce type permettra à notre avis de mettre
en
évidence des irrégularités qui n'auraient pu être
révélées par une analyse moins
méthodique. Par exemple, sur l'échantillon que nous avons étudié,
nous remarquons que
près de 99% des articles standard comportent un champ grammatical (c'est-à-dire,
330
sur 334 articles standard, 16 articles de renvoi ayant été exclus; cf. plus loin en 3).
Nous
considérons ce champ comme obligatoire dans notre structure type et les articles dans
lesquels cette information n'est pas présente comporteront une balise vide. Nous voyons
un exemple de ce traitement dans la figure 1. Une balise
<Gramgrp> pour la partie
grammaticale) est introduite pour l'article DECISIF alors que cette information n'est pas disponible
dans l'article, contrairement au sous-article DEBARASSÉ.
|
DECISIF, IVE. Qui decide; qui resoud […]
<Gramgrp>
<Pos Type = ADJ> </Pos>
</Gramgrp>
DEBARASSÉ, ÉE. part.pass. & adj. […]
<Gramgrp>
<Pos Type = PPSE>part. pass. </Pos>
</Gramgrp> &
<Gramgrp>
<Pos Type = ADJ>adj. </Pos>
</Gramgrp>
|
|
Fig. 1. Un exemple de balisage de la partie grammaticale
Ce traitement permettra au spécialiste des dictionnaires d'effectuer des études
statistiques sur
l'absence de certains champs, phénomène qui est en soi une information
d'importance.
Par ailleurs, l'utilisation d'une structure type nous permet de régulariser certaines
informations,
comme les marques grammaticales qui présentent une certaine variété de
forme. Ainsi, la
marque indiquant le substantif se présente sous plusieurs
formes : « s. », « subst », « S. »,
« substantif » (cf. plus loin en 3.3). Il faut donc être un
véritable spécialiste du dictionnaire
pour effectuer une interrogation pertinente sur ce champ, n'engendrant ni bruit (parmi les
réponses, certaines ne sont pas pertinentes), ni silence (des informations pertinentes n'ont
pas
été sélectionnées par la requête). Pour systématiser les
informations, nous avons utilisé des
attributs qui, associés aux éléments permettent non seulement de normaliser
une information
qui se présente sous plusieurs formes, mais aussi de coder explicitement une information
implicite ou absente. Par exemple, nous avons introduit pour l'article DECISIF non seulement
une balise <Gramgrp>, mais aussi une balise vide
<Pos> (pour la partie du discours). À cette
dernière, on associe un attribut Type qui prend la
valeur « adj ». Cela permet d'effectuer une
interrogation sur cet article à partir de la partie du discours (requête qui pourra
intéresser
l'historien de la langue), bien que cette information ne soit pas explicitement présente. Ce
type
de codage à l'aide d'attributs peut paraître à juste raison un peu redondant
puisque dans la
grande majorité des cas, l'information grammaticale est déjà fournie par le
texte d'origine, mais
comme il sera effectué semi-automatiquement à l'aide de transducteurs comme on
le verra plus
loin en 3.3, il ne sera pas trop lourd à effectuer. Nous préférons ce type de
balisage aux
« mots-clés métalinguistiques » proposés par T.R.
Wooldridge et I. Leroy Turcan (Wooldridge & Leroy-Turcan 1996) [6] dans la mesure
où cette méthode ne permet pas de
repérer l'information implicite.
2.3. Utiliser des automates finis pour effectuer un balisage semi-automatique
S'appuyer sur des indices formels permet de mettre au point des méthodes d'analyse
rigoureuses et reproductibles d'une personne à l'autre. De nombreux champs
informationnels (la
typographie, la distribution des éléments dans l'article et les marques
métalinguistiques)
apparaissent suffisamment réguliers pour que l'on envisage d'automatiser partiellement le
balisage
en associant un ensemble de balises à des patrons prédéfinis. Le recours
à des modèles
informatiques de ce type présente de nombreux avantages. Il permet en effet :
de formaliser très précisément les marques sur lesquelles se fondera
le balisage. Toutes les
marques et tous les patrons apparaissant dans les champs doivent en effet être décrits
exhaustivement et finement pour réaliser le balisage semi-automatiquement. L'analyse
métalexicographique des dictionnaires gagne en rigueur;
de garantir une cohérence interne au traitement. Ainsi, les fautes de frappe et les
oublis,
inévitables dans le cas d'un balisage manuel, sont évités;
d'accélérer le processus de balisage. Bien entendu, certains champs se
prêtent mieux que
d'autres à ce traitement. Les champs très structurés comme l'entrée
ou la partie
grammaticale peuvent plus facilement être analysés par des automates que la
définition ou
la partie encyclopédique. De plus, il reste indispensable de vérifier le traitement
effectué par
l'automate. L'analyse demeure donc bien « semi-automatique ».
Le modèle informatique que nous utilisons sont les automates finis. Ceux-ci peuvent
être
schématiquement définis comme des graphes qui décrivent des parcours
possibles d'un état
initial à des états finals.
Pour automatiser le balisage, nous décrivons les micro-langages qui apparaissent dans
les
articles : langage de l'entrée et des sous-entrées, langage de la zone
grammaticale, langage de
la zone décrivant le domaine, etc. Pour formaliser les automates décrivant les
champs
informationnels de l'article, nous utilisons l'outil INTEX qui a été
élaboré au LADL par Max
Silberztein (Silberztein 1993). Ce logiciel permet de reconnaître des automates finis et
de
manipuler des transducteurs (automates qui associent aux entrées des sorties)
adaptés au
langage naturel grâce à de très gros dictionnaires du
français [7] (dictionnaires DELAS et
DELAF du LADL [8]). Grosso modo, le logiciel
permet de reconnaître des suites comportant des
mots (fléchis ou non) et/ou des catégories grammaticales et d'assigner à
ces « patrons » des
étiquettes. C'est un produit facilement manipulable et très puissant.
Dans la figure 2, nous présentons un exemple de graphe permettant de
reconnaître les parties
grammaticales des entrées substantivales. Ce graphe est plus précisément
un transducteur,
c'est-à-dire un automate qui associe au parcours de chaque état
une « sortie ». Le nœud initial
de l'automate est soit une esperluette, soit une virgule, soit un point. Le nœud suivant est
vide
et produit sur sa gauche la
chaîne « <GramGrp > » (la
sortie). Ensuite, dès que la chaîne
« s. », « subst. »
ou « substantif » est rencontrée, la
balise « <Pos Type=s> » est produite,
quelle que soit la forme de surface. Puis, apparaît l'information sur le genre, d'ailleurs
répétable, qui sera aussi normalisée à l'aide d'un attribut. Une
information sur le nombre,
principalement sur les pluralia tantum, peut aussi apparaître. Le transducteur
fonctionne s'il a
pu atteindre l'état final d'une façon ou d'une autre [9]. Dans cet exemple, comme on peut le voir
Fig. 3, des chaînes comme « & s.m. »
ou « substantif masculin pluriel. » seront reconnues,
mais des chaînes comme « & s masculin »
ou « .s .pl.» ne seront pas analysées par l'automate
(dans le premier cas, il manquera un point ; dans le second cas, il manquera l'information
sur
le genre).
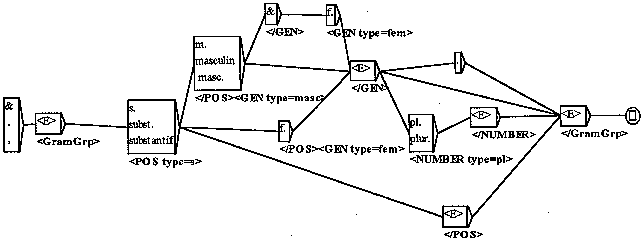
Fig 2 : Un exemple de transducteur pour les parties grammaticales
des vedettes substantivales
| En entrée | | En sortie |
|---|
|
| & s.m. | | <GramGrp><POS
type=s>s.</POS><GEN>m.</GEN></GramGrp> |
Substantif masculin
pluriel. | | <GramGrp><POS>substantif</POS><GEN>
masculin</GEN><NUMBER>pluriel</NUMBER></GramGrp> |
| & s masculin | | ECHEC |
| .s. pl. | | ECHEC |
|
Fig 3 : Quelques exemples d'analyses à l'aide du
transducteur de la Fig. 2
Dans l'état de nos travaux, des transducteurs ont été
élaborés pour les entrées principales
et les sous-entrées, la partie grammaticale et un sous-ensemble des marques de domaine.
Nous
envisageons d'étendre cette technique à d'autres champs informationnels tels que
les citations,
les renvois et les marques d'usage.
[Table] -- [Suite]
Notes
1. Estelle Bultez, titulaire du Diplôme
Européen de Lexicographie, et Anne-Lise
Teneul, actuellement en maîtrise des Sciences du Langage à
l'Université Lille 3.
2. On distinguera les normes, qui sont « un
ensemble de règles d'usage, de presciptions
techniques, relatives aux caractéristiques d'un produit ou d'une
méthode, édictées dans le but
de standardiser et de garantir les modes de fonctionnement, la
sécurité et les nuisances »
(Nouveau Petit Robert, 1993), des standards qui sont des
conventions adoptées par une
communauté, sans qu'un comité de normalisation ait
présidé à leur conception. SGML est une
norme internationale ISO, mais les recommandations de la « Text Encoding
Initiative » ne
constituent pas une norme.
3. La « Text Encoding Initiative »
a été subventionnée par les associations et organismes
suivants : Association for Computers and the Humanities, Association
for Computational Linguistics,
Association for Literary and Linguistics Computing, U.S. Endowment for the
Humanities,
Commission des communautés européennes (CEC/DGXII), the Andrew
W. Mellon Foundation, the
Social Science and Humanities Research Council of Canada.
4. Les attributs sont associés aux
éléments et permettent d'affiner la description de
ceux-ci. Par exemple, dans <Form
Type=phrase><Orth>D'ABORD</Orth></Form>,
<Form> et <Orth> sont des
éléments qui isolent les parties textuelles, alors que
Type=phrase
(composé) est un attribut qui permet d'affiner l'information
concernant les éléments.
5. Cet accès à une copie du texte
original est prévu dans la base échantillon Académie
(http://www.chass.utoronto.ca/~wulfric/academie/) et dans la base
échantillon Nicot
(http://www.chass.utoronto.ca/~wulfric/nicot/).
6. Les mots-clés métalinguistiques sont
des marques conventionnelles correspondant à des listes
de marques métalinguistiques apparaissant dans les dictionnaires. Ces
éléments peuvent générer du
bruit (des informations non pertinentes peuvent être extraites, par
exemple, substantif qui peut
renvoyer à une information qui ne concerne pas directement
l'information grammaticale) et du
silence (l'information qui n'est pas codée explicitement ne peut pas
être repérée).
7. Les dictionnaires utilisés par
INTEX sont adaptables à la langue et au lexique du
XVIIIème.
Ce travail peut être envisagé dans une seconde étape.
8. « Voir Les dictionnaires électroniques »,
Langue Française, Larousse, n°87, 1990.
9. Le symbole <E> permet
d'analyser des chaînes vides.